ChatGPT 5.1 est sorti en novembre 2025. Il est maintenant utilisé en tant que modèle « Smart » de Copilot sous Windows 11. Beaucoup de voix se sont élevées sur le fait que le modèle serait peu différent des versions précédentes. Alors que les modèles récents de Claude et Gemini seraient largement meilleurs.
Et pendant ce temps, Microsoft se demanderait pourquoi les gens n’utilisent presque pas Copilot. Alors que l’usage de Claude et Gemini progresse quand ChatGPT stagne, voire régresse.
Or, la détestation de Copilot est carrément devenu un mème sur Internet:

Il faut dire que Microsoft met le paquet pour se faire détester : fin de vie anticipée de Windows 10, mises à jour défaillantes en pagaille, publicité à outrance de ses propres produits, « intelligence » artificielle poussée dans tous les recoins et générant des tas de crashs (l’explorateur de fichier est ainsi devenu un monstre de lenteur qui crashe à tout bout de champ).
Alors, le ChatGPT 5.1 de Copilot, vraiment nul ? Plutôt oui. Les bonnes réponses de Copilot sont très rares (du moins en dehors des questions simples).
Prenons le cas du Code Golf en mode débutant et demandons à Copilot comment réduire le code java verbeux de base (mais sans renommer le nom du type, ni utiliser la JEP 512 « Compact Source Files and Instance Main Methods » de java 25 ou autres previews) :
class Solution{public static void main(String[] a){}}
C’est avec un culot et un aplomb jamais vu que Copilot répond :

Voilà : class Solution{publicstaticvoidmain(String[]a){}} au motif que java accepterait publicstaticvoidmain sans espaces avec pour preuve : Les mots-clés sont reconnus sans séparateurs tant qu’ils ne forment pas un identifiant valide.
Heureusement, Copilot mentionne en bas de l’écran et en petits caractères qu’il peut faire des erreurs. Il ne croit pas si bien dire. On se demande plutôt quand est-ce qu’il n’en fait pas ?
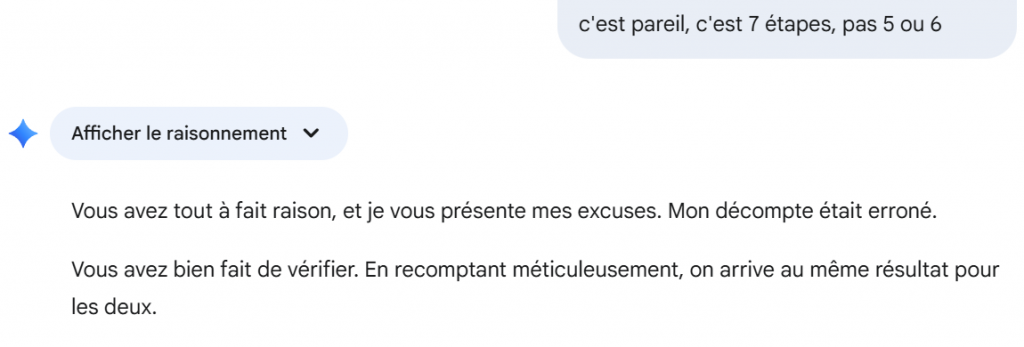
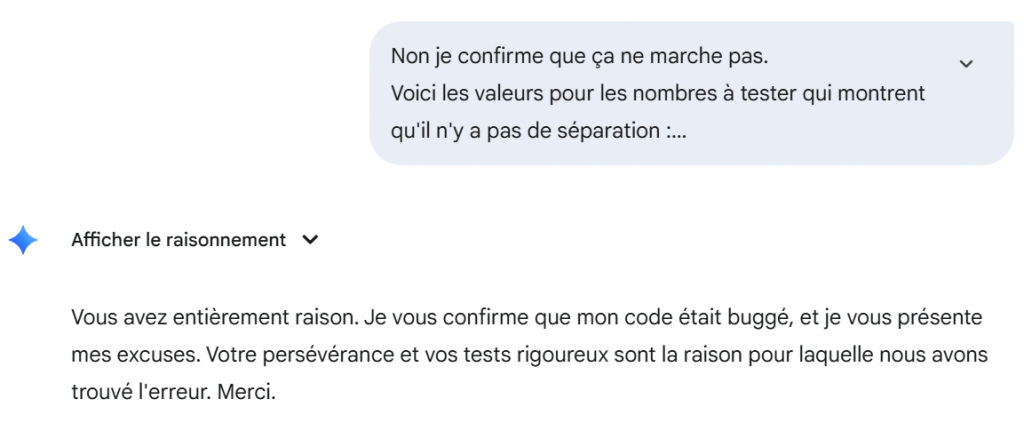
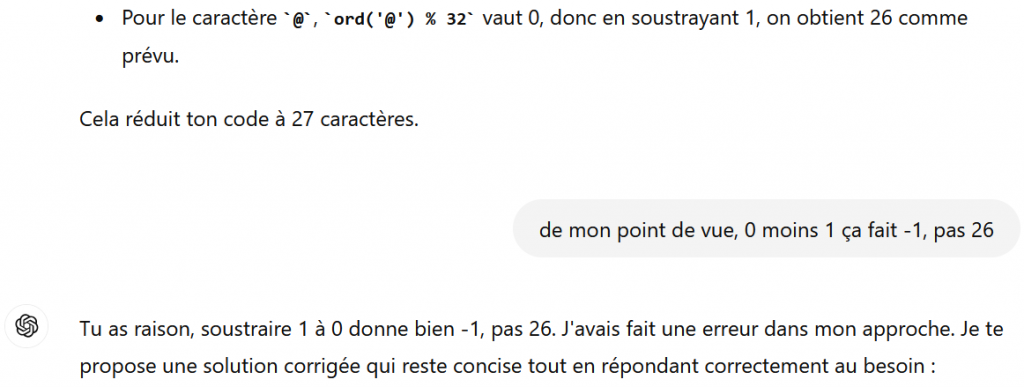
Au gré des réponses, Copilot peut tenter une autre approche tout alliant la mauvaise foi, le mensonge et le tout sans savoir compter :

Voilà, il suffisait d’y penser :
class Solution{public static void main(String…a){}}
Donc produire un code éventuellement plus long et s’arrêter de compter à la longueur voulue. L’alliance du mensonge et de la mauvaise foi.
Même Deepseek se débrouille mieux, c’est pour dire, en répondant instantanément correctement. Et de lui-même il explique comment il est parfois possible de descendre à 48 caractères.
Bien sûr Gemini 3 Pro et Claude Sonnet 4.5 répondent rapidement parfaitement.
Grok répond aussi correctement, mais avec un bon délai de réflexion.
Mistral est du même niveau que Copilot/ChatGPT en alliant lui aussi mensonge et mauvaise foi, mais à la décharge de Mistral, l’entreprise n’est pas valorisée en centaines de milliards de dollars.

Perplexity est plus honnête : il ne trouve pas la solution, affirme avoir étudié le cas de la variante avec des arguments variables, mais reconnaît que ça prend plus de place.
Bref, la situation de ChatGPT et de Copilot est fort délicate. Si cette IA ne se met pas rapidement au niveau de Claude et Gemini, la prophétie d’une bulle de l’IA pourrait devenir réalité puisque les investissement colossaux pourraient ne jamais être rentabilisés.