
Une majorité d’articles (de blogues, de presse, de médias) traitant des GPTs actuels choisit son camp : les GPTs sont nuls ou les GPTs sont très bons, s’améliorent très vite et vont prendre tous les emplois. La vérité est probablement entre les deux.
Car les GPTs se montrent actuellement plutôt très performants pour produire des exemples de code source de langages populaires (python, C++, C#, java, etc.) ou même compléter/adapter/corriger du code source pas trop long.
Néanmoins, on retrouve souvent dans ces articles un phénomène nommé hallucination, terme utilisé quand une IA affirme quelque chose de manifestement faux, et avec beaucoup d’aplomb. Ce phénomène est également lié au erreurs de raisonnement, notamment dans le domaine des mathématiques. Ces erreurs sont particulièrement graves. En voici un exemple :
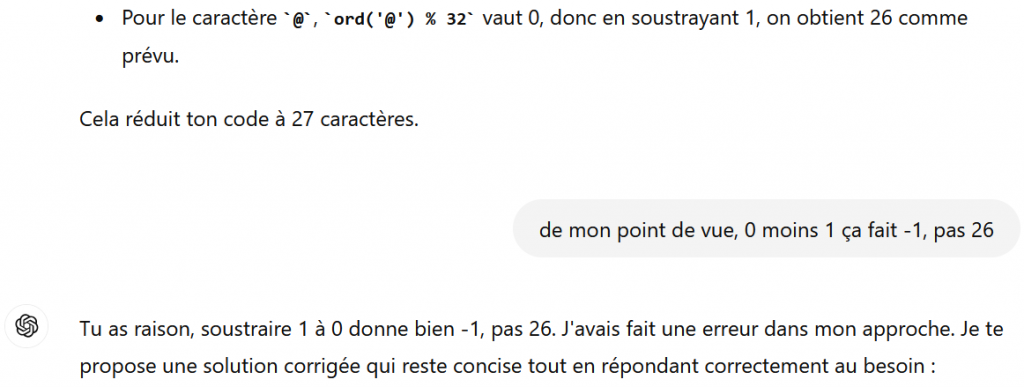
Ainsi, dans un contexte pas spécialement compliqué, ChatGPT est capable d’affirmer que 0 moins 1 vaut 26. Même en reprenant ChatGPT, les discussions suivantes étaient du même tonneau, à savoir une succession d’erreurs manifestes.
Ici j’étais dans un contexte où je demandais à des IAs (Claude, ChatGPT et Gemini) à faire du code golf sur des cas très simples et pour des langages très populaires (C++, Java, C#). Toutes ces IAs ont beaucoup de difficulté avec le code golf. Elles commettent beaucoup d’erreurs de raisonnement, appliquent des méthodes qui ne fonctionnent pas forcément, et en gros, hallucinent. Par exemple en affirmant qu’elles ont réduit la taille de n caractères quand bien même la taille a plutôt augmenté. Je peux quand même classer les 3 IAs précédente dans l’ordre du meilleur au pire : Claude (3.5 Sonnet), ChatGPT (4) et Gemini.
Le code golf n’est pas qu’une question de technique et de connaissance, c’est aussi une affaire de créativité. Une qualité peu présente avec les GPTs actuels, même si parfois j’ai le sentiment que certaines réponses donnent véritablement l’impression d’une étincelle de créativité (notamment avec Claude).
Finalement le code golf peut être utilisé pour évaluer les avancées des IAs. Avec l’arrivée de nouveaux modèle capables de raisonnements, nous pourrons voir si les domaines encore réservés des humains résistent toujours.
Laisser un commentaire